How to Read Data From Kafka Topic Using Spark Streaming
Streaming Data from Apache Kafka Topic using Apache Spark 2.4.7 and Python
Creating a CDC data pipeline: Part ii

Outline
- Introduction
- Creating Security Groups and EC2 Instances (~5 min)
- Installing/Configuring Spark (~v min)
- Starting All Pipeline Services (~10 min)
- Extracting CDC Row Insertion Data Using Pyspark (~fifteen min)
- Running Ain Functions on Output
- Changing the Spark Job to Filter out Deletes and Updates
- Completed Python File
- Annex
Introduction
This is the second part in a three-part tutorial describing instructions to create a Microsoft SQL Server CDC (Alter Data Capture) data pipeline. However, this tutorial can work as a standalone tutorial to install Apache Spark two.4.7 on AWS and employ it to read JSON data from a Kafka topic.
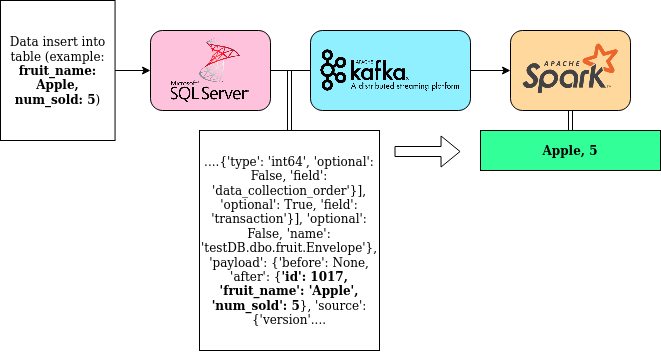
By the cease of the first two parts of this tutorial, you will have a Spark task that takes in all new CDC information from the Kafka topic every two seconds. In the case of the "fruit" table, every insertion of a fruit over that 2 second period will be aggregated such that the full number value for each unique fruit will be counted and displayed.
NOTE: This tutorial assumes y'all are only working with inserts on the given table. Y'all may demand to edit the Spark transformation to filter specific kinds of CDC information based on the "op" parameter in CDC data. This is discussed near the finish of tutorial.
Step 1: Creating Security Groups and EC2 Instances (~five min)
NOTE: this setup assumes you lot accept created an EC2 instance with Kafka installed and running in your default VPC. Refer here for instructions on that if needed.
Create an AWS instance with the following settings. Accept defaults where details are left unspecified.
Apache Spark AWS Details:
- Image blazon: Ubuntu Server xviii.04 LTS (HVM)
- Minimum recommended example blazon: t2.medium
- Number of instances: 1
- Inbound Security Rules: SSH from My IP; All TCP from default VPC CIDR
Pace 2: Installing/Configuring Spark (~5 min)
- Log into the Ubuntu eighteen.04 instance using an SSH client of your option.
- Update the Apt repos and install Java JDK 8.
sudo apt-get update -y;
sudo apt-become install openjdk-viii-jdk -y; - Download the Spark 2.4.7 package with Hadoop and extract the files.
wget http://mirror.cc.columbia.edu/pub/software/apache/spark/spark-2.4.7/spark-two.4.seven-bin-hadoop2.7.tgz; tar -xvzf spark-two.4.7-bin-hadoop2.7.tgz;
- Brand an "/etc" directory for Spark, change the ownership to the "ubuntu" user, and copy the Spark files in.
sudo mkdir /etc/spark;
sudo chown -R ubuntu /etc/spark;
cp -r spark-2.four.vii-bin-hadoop2.7/* /etc/spark/; - Copy the Spark environment template file.
cp /etc/spark/conf/spark-env.sh.template /etc/spark/conf/spark-env.sh - Add the following lines to the end of the copied file and so Spark uses Python iii for Pyspark jobs.
PYSPARK_PYTHON=/usr/bin/python3
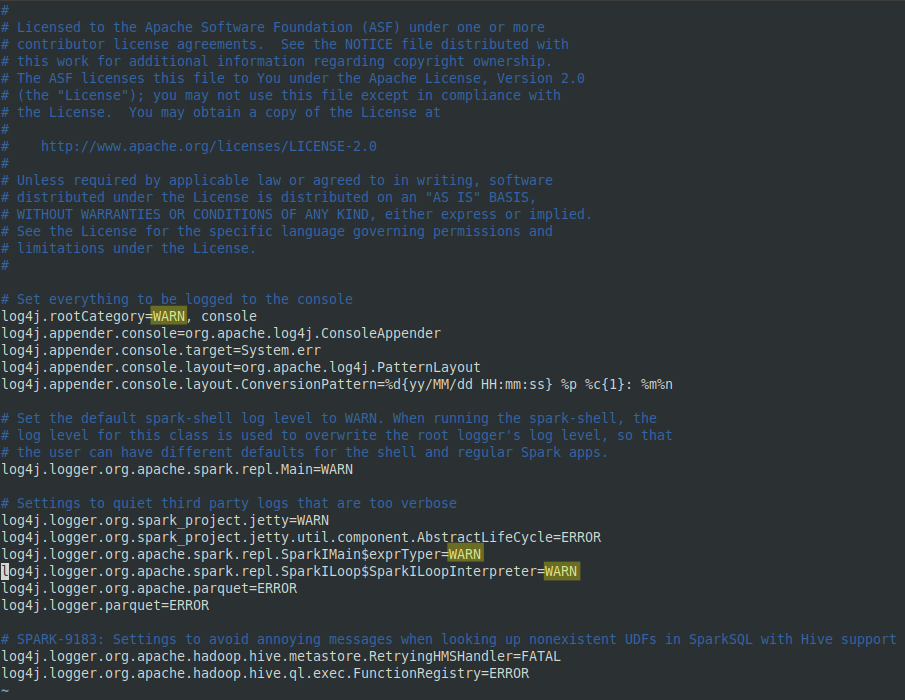
PYSPARK_DRIVER_PYTHON=/usr/bin/python3 - (Optional) Re-create the log properties template file and change any instances of "INFO" to "WARN". This volition reduce screen ataxia when viewing live Spark streams.
cp /etc/spark/conf/log4j.properties.template /etc/spark/conf/log4j.backdrop 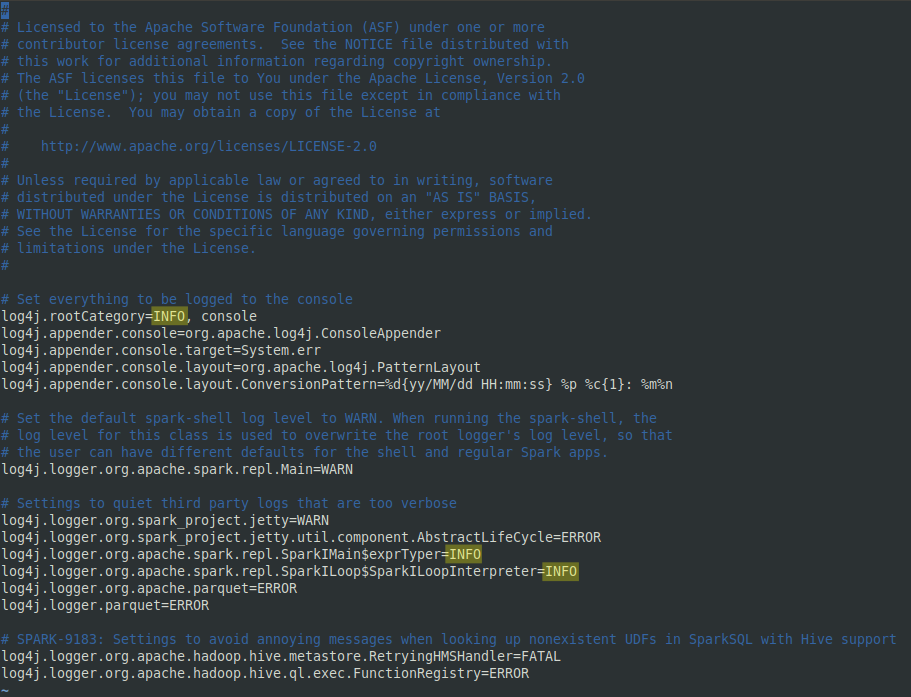
- Install Pip (Python Package Installer) for Python 3 and install the "findspark" parcel.
sudo apt-get install python3-pip -y;
sudo pip3 install findspark;
sudo pip3 install pyspark; Step three: Starting All Pipeline Services (~10 min)
NOTE: Call up to check any IP address configurations as they might alter.
- RDP into the Windows Server instance.
- Open an admin Powershell.
- Brand sure the MS SQL Server SQL Server Agent services are running.
net start MSSQLSERVER
net starting time SQLSERVERAGENT 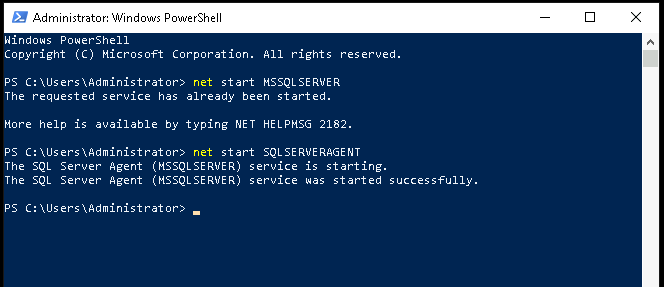
- SSH into the Apache Kafka Ubuntu case.
- First the Kafka Zookeeper, Banker, and Connect programs.
/etc/kafka/bin/zookeeper-server-offset.sh /etc/kafka/config/zookeeper.properties &> zookeeper_log & /etc/kafka/bin/kafka-server-first.sh /etc/kafka/config/server.properties &> broker_log & /etc/kafka/bin/connect-distributed.sh /etc/kafka/config/connect-distributed.properties &> connect_log &
- Make sure the Debezium connector is added with the first control. If it isn't, edit and use the second command to add it once more.
curl -H "Accept:application/json" localhost:8083/connectors/; curl -i -X POST -H "Accept:application/json" -H "Content-Blazon:application/json" localhost:8083/connectors/ -d '{ "name": "test-connector", "config": { "connector.class": "io.debezium.connector.sqlserver.SqlServerConnector", "database.hostname": "{Individual IP Address}", "database.port": "1433", "database.user": "testuser", "database.password": "password!", "database.dbname": "testDB", "database.server.name": "testDB", "table.whitelist": "dbo.fruit", "database.history.kafka.bootstrap.servers": "localhost:9092", "database.history.kafka.topic": "dbhistory.fulfillment" } }';


NOTE: Refer to the first part of this tutorial for more than detailed instructions for starting Kafka and MS SQL services.
NOTE: Make sure CDC data is appearing in the topic using a consumer and brand sure the connector is installed every bit information technology may be deleted when Kafka Connector goes down. You may need to bank check any IP address configurations.
Stride 4: Extracting CDC Row Insertion Data Using Pyspark (~15 min)
Running a Pyspark Job to Read JSON Data from a Kafka Topic
- Create a file chosen "readkafka.py".
bear upon readkafka.py - Open the file with your favorite text editor.
- Re-create the following into the file.
#Imports and running findspark
import findspark
findspark.init('/etc/spark')
import pyspark
from pyspark import RDD
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
import json
#Spark context details
sc = SparkContext(appName="PythonSparkStreamingKafka")
ssc = StreamingContext(sc,2)
#Creating Kafka direct stream
dks = KafkaUtils.createDirectStream(ssc, ["testDB.dbo.fruit"], {"metadata.broker.listing":"|supercede with your Kafka private address|:9092"})
counts = dks.pprint()
#Starting Spark context
ssc.showtime()
ssc.awaitTermination()
NOTE: THIS Section OF THE TUTORIAL Will Go OVER ITERATIONS OF THE ABOVE PYTHON FILE. IF You lot Want THE COMPLETED FILE, SCROLL TO THE Bottom OF THIS SECTION.
- Save the file and close it.
- Run a Pyspark chore past running the below. If it works, y'all should first seeing timestamps separated past two seconds.
/etc/spark/bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:ii.2.3,org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.3 readkafka.py 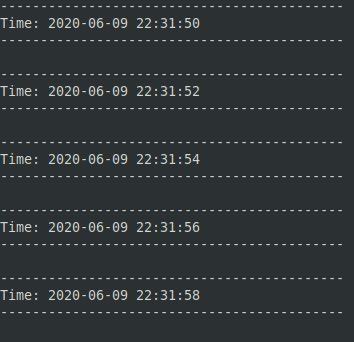
- Start calculation data to the Kafka topic by running an insert on the "fruit" tabular array on the MS SQL Server instance. Y'all will see the entire JSON output in the Spark window.
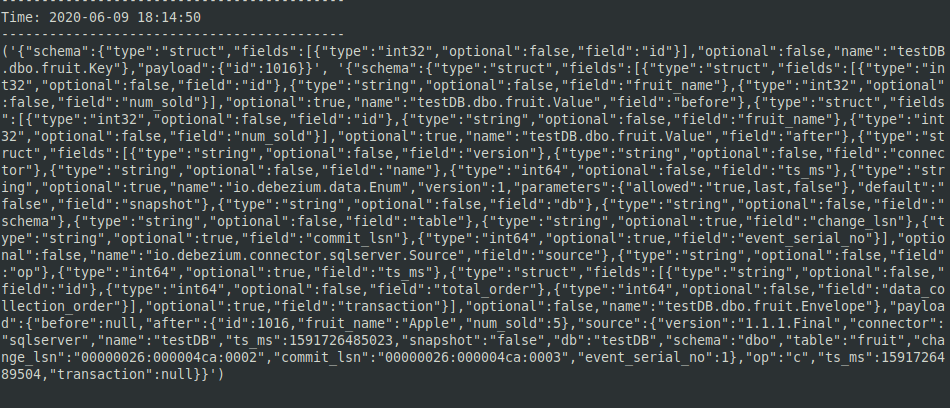
- Notice that the JSON data is packaged inside a Python tuple. We volition accept to edit the Python program to extract the JSON from the tuple.
- Printing "CTRL + C" to end the Spark context.
Extracting JSON data from tuple
- Change the post-obit line.
# To excerpt JSON data from the tuple, modify this...
counts = dks.pprint() # To this...
counts = dks.map(lambda x: json.loads(x[1])).pprint()
- Save the file and run the Pyspark chore over again.
- Insert another row into the fruit table.
- Observe that the Spark window now shows the JSON information extracted from the tuple.
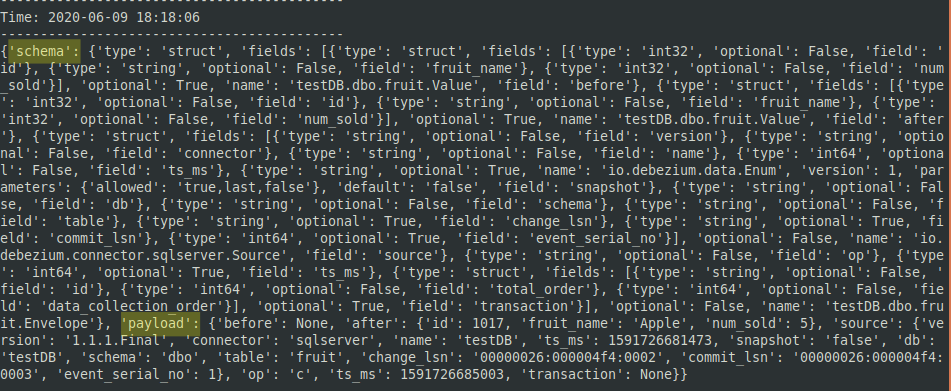
- Discover that there are two master entries in this JSON list: "schema" and "payload". In this case, we volition need to extract the "payload". We volition begin by isolating the "schema" and the "payload" into separate tuples.
- Press "CTRL + C" to cease the Spark context.
Separating major sections of CDC JSON data
- Change the following line in "readkafka.py".
# To separate the schema and the payload, change this...
counts = dks.map(lambda x: json.loads(x[1])).pprint() # To this...
counts = dks.map(lambda 10: json.loads(x[i])).flatMap(lambda dict: dict.items()).pprint()
- Relieve the file and run the Pyspark job again.
- Insert some other row into the fruit table.
- Observe that the schema and payload sections are separated into different tuples.
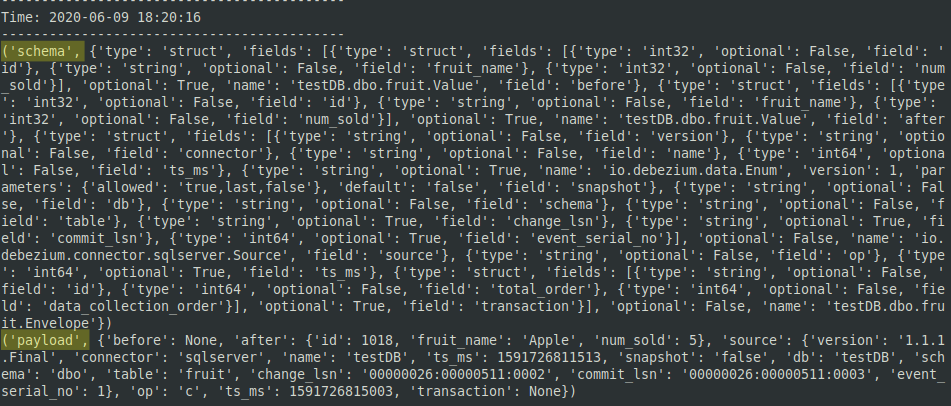
- At present nosotros volition need to further transform the data by isolating the payload.
- Press "CTRL + C" to finish the Spark context.
Isolating tabular array modify data
- Alter the following line in "readkafka.py".
# To isolate the payload, alter this...
counts = dks.map(lambda ten: json.loads(10[1])).flatMap(lambda dict: dict.items()).pprint() # To this...
counts = dks.map(lambda x: json.loads(x[1])).flatMap(lambda dict: dict.items()).filter(lambda items: items[0]=="payload").pprint()
- Relieve the file and run the Pyspark chore once more.
- Insert another row into the fruit table.
- Notice that at present only the payload is visible.

- We will need to extract the data from the row inserted. This is found in the "after" section of the payload.
- Printing "CTRL + C" to end the Spark context.
Extracting insertion data
- Change the following line in "readkafka.py".
# To get insertion data, change this...
counts = dks.map(lambda x: json.loads(ten[1])).flatMap(lambda dict: dict.items()).filter(lambda items: items[0]=="payload").pprint() # To this...
counts = dks.map(lambda x: json.loads(10[1])).flatMap(lambda dict: dict.items()).filter(lambda items: items[0]=="payload").map(lambda tupler: (tupler[1]["after"]["fruit_name"], tupler[1]["subsequently"]
- Save the file and run the Pyspark job again.
- Insert another row into the fruit table.
- Discover that insertion data is returned in a tuple (this row inserted a fruit called "Apple" with a number value of 5).
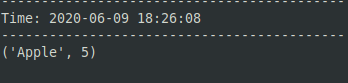
- Observe if multiple insertions happen inside two seconds of each other.
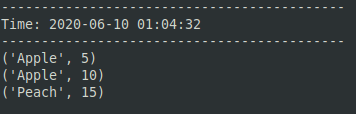
- The final step is to add the number values based on key. This is chosen reducing.
- Printing "CTRL + C" to end the Spark context.
Reducing by fruit proper name
- Change the following line in "readkafka.py".
# To become reduce by key, change this...
counts = dks.map(lambda ten: json.loads(10[one])).flatMap(lambda dict: dict.items()).filter(lambda items: items[0]=="payload").map(lambda tupler: (tupler[i]["later on"]["fruit_name"], tupler[i]["after"] # To this...
counts = dks.map(lambda x: json.loads(x[one])).flatMap(lambda dict: dict.items()).filter(lambda items: items[0]=="payload").map(lambda tupler: (tupler[1]["afterwards"]["fruit_name"], tupler[ane]["subsequently"]["num_sold"])).reduceByKey(lambda a, b: a+b).pprint()
- Save the file and run the Pyspark job again.
- Run at least two insertions within two seconds of each other with the same fruit proper name. You should see the numbers added together.
- Press "CTRL + C" to end the Spark context.
Step v: Running Ain Functions on Output
While press aggregated CDC data is interesting, it is inappreciably useful. If you want to run your ain functions (whether to store the information on the Spark node or stream it elsewhere), changes demand to be made to the completed file. One way to do information technology is to substitute the "pprint()" function for "foreachRDD" so that each reduced set of fruit and totals tin have a role run on them.
# To program your own behavior, change this...
counts = dks.map(lambda x: json.loads(x[i])).flatMap(lambda dict: dict.items()).filter(lambda items: items[0]=="payload").map(lambda tupler: (tupler[i]["afterward"]["fruit_name"], tupler[1]["after"]["num_sold"])).reduceByKey(lambda a, b: a+b).pprint() # To this...
counts = dks.map(lambda x: json.loads(x[1])).flatMap(lambda dict: dict.items()).filter(lambda items: items[0]=="payload").map(lambda tupler: (tupler[1]["after"]["fruit_name"], tupler[i]["afterwards"]["num_sold"])).reduceByKey(lambda a, b: a+b).foreachRDD(somefunction)
Once this is washed, custom functions can be run by replacing "somefunction" above with the function proper noun. Here is an example part that will exercise the aforementioned beliefs as "pprint()", but, by virtue of the format the Kafka data is read into Spark, volition exit out superfluous timestamps.
def printy(a, b):
listy = b.collect()
for fifty in listy:
print(fifty) counts = dks.map(lambda x: json.loads(x[1])).flatMap(lambda dict: dict.items()).filter(lambda items: items[0]=="payload").map(lambda tupler: (tupler[1]["afterward"]["fruit_name"], tupler[1]["after"]["num_sold"])).reduceByKey(lambda a, b: a+b).foreachRDD(printy)
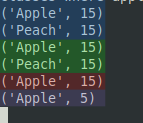
Notice that there are four unlike aggregation events with no timestamps betwixt them and prints nothing if no insertions happen. With a piddling scrap of editing this function tin export these values to a separate programme that can track the totals for each fruit over different spans of time. This will be covered in the final part of this tutorial.
Step 6: Changing the Spark Chore to Filter out Deletes and Updates
Updates and deletes are not considered. If you crave updates and deletes to be filtered out, it volition accept some piece of work with Python logic and some extra filtering of the JSON data. This will be based on the "op" parameter found at the end of each JSON data string.



Completed Python File
The below file, when submitted equally a Spark chore with /etc/spark/bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:two.2.3,org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.3 readkafka.py, takes in all new CDC information from the Kafka topic every two seconds. In the instance of the "fruit" table, every insertion of a fruit over that two second flow will be aggregated such that the full number value for each unique fruit will be counted and displayed.
#Imports and running findspark
import findspark
findspark.init('/etc/spark')
import pyspark
from pyspark import RDD
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
import json
#Spark context details
sc = SparkContext(appName="PythonSparkStreamingKafka")
ssc = StreamingContext(sc,2)
#Creating Kafka direct stream
dks = KafkaUtils.createDirectStream(ssc, ["testDB.dbo.fruit"], {"metadata.broker.list":"{supercede with your Kafka private address}:9092"})
# Transforming CDC JSON data to sum fruit numbers
# based on fruit name
def printy(a, b):
listy = b.collect()
for l in listy:
print(l)
counts = dks.map(lambda x: json.loads(x[1])).flatMap(lambda dict: dict.items()).filter(lambda items: items[0]=="payload").map(lambda tupler: (tupler[1]["after"]["fruit_name"], tupler[one]["after"]["num_sold"])).reduceByKey(lambda a, b: a+b).foreachRDD(printy)
#Starting Spark context
ssc.offset()
ssc.awaitTermination()
Annex
In the adjacent part of this tutorial, we will install Grafana, Graphite Carbon, and Graphite Web onto an Ubuntu 18.04 EC2 instance to stream and plot the CDC data transformed by Spark. The Spark Python job from this tutorial will besides be edited to use StatsD to interface with Graphite Carbon. A link volition be added HERE when Part 3 is available.
Source: https://sandeepkattepogu.medium.com/streaming-data-from-apache-kafka-topic-using-apache-spark-2-4-5-and-python-4073e716bdca
0 Response to "How to Read Data From Kafka Topic Using Spark Streaming"
Post a Comment